학습목표
글자 단위의 기계번역을 학습합니다. 또한 실험결과를 통해 다중언어 기계번역으로 확장시킵니다.
핵심키워드
- 기계 번역(Machine Translation)
- 형태(Morphology)
- 글자 단위 모델링(Character-level Modeling)
- Fully Character-level Machine Translation
학습하기
보통 기계 번역이라고 하면, 문장을 단어로 분할하고, 그 단어에 대한 어떤 번역을 하는 과정을 자연스럽게 떠올리죠. 그런데, 살짝 다시 생각을 해보면, Neural Net을 사용할 때, 그렇게 해야만하는가-하는 생각이 드는거죠. 문장이 단어로 이루어져있든, 알파벳 하나하나 캐릭터로 이루어져있든, 이모지가 들어가 있든, 사실 그냥 인코딩만 할 수 있다면, 연속 벡터 공간으로 임베딩만 시키면 다음은 다 똑같죠. 컴퓨터에 입장에서는 어떤 거든 결국 다 똑같은거에요. 그냥 숫자로 이루어진 시퀀스 데이터인거죠. 정수든, 원핫이든. 그럼 이 상황에서 궁금한건, 전처리를 최소로 할 수 있는게, 어디까지인가. 내가 단어로 분할한다면 서브워드니 토큰화니 스테밍이니 여러 과정이 필요하겠죠.

사실 그런 측면에서 우리는 아래와 같은 단계들을 밟아왔어요. 처음에는 단어 단위로 했는데, 이렇게 하다보니까 Vocabulary가 너무 커지는 문제가 있었죠. 특히 합성어가 있는 언어들의 경우 거의 무한이 될 수도 있죠. 그래서 Subwords를 잘 Segmentation하기 위한 많은 방법론들이 연구되었는데, 한번 인코딩이 되고 나면, Neural Net안에서 워낙 잘 처리하다보니, 굳이 복잡한 기법을 쓰지않아도 된다라는 결론이 나왔고, 현재는 가장 베이직한 방법론인 Byte Pair Encoding, BPE만으로도 왠만하면 충분합니다. 그 다음이 이제 스탠포드에서 연구했던 내용인데, 이 문장이라는게, 결국 글자들의 시퀀스의 시퀀스다. 그래서 Hierachical하게 RNN을 학습시키는 방법이 등장했죠. Welcome, to, Montreal 이 3개 각각에 RNN을 적용하여 벡터를 얻어내고, 그렇게 얻어진 3개의 벡터 전체를 다시 RNN에 적용하는. 그런 방식이 되겠죠. 다만 이런 경우, 코드가 굉장히 지저분해집니다. 그래서 저는 선호하지 않구요. 그래서 다음에 나온게, 아 그럼 그냥, Char 단위 시퀀스로 보면 되지 않나-하는 거죠.

그럼 Char 단위 시퀀스로 바라봐야한다는 이야기를 하기 전에, 왜 단어 단위의 모델링이 좋지 않은가-에 대해 이야기를 해보죠. 첫번째는, Morph단위를 핸들링하는 것 자체가 좀 어렵습니다. 일단 Vocabulary 수가 굉장히 많아지구요. 과학기술정보통신부 같은 예시를 하나 들었는데, 이게 정권이 바뀌면 이름이 바뀌기도 하고, 이런 단어들이 생각보다 많죠. 두번째로는, SNS같은게 발전하면서 나타난게 Misspelling이 굉장히 많아졌는데, 이런게 모이면 Neural Net에게 부담이 되죠. 그리고 could -> cld, would -> wld 같은 줄임말들이, 사람에게는 너무나 단순한 패턴인데, 기계가 이해하기에는 이 단어 단위 모델링이 별로 큰 도움을 못주는거죠. 세번째는, 단순하게 생각하면, 단어마다 길이가 다르죠. 그럼 사실 길이가 굉장히 긴 단어와, 굉장히 짧은 단어는 정보량이 다를 수 있습니다. 그런데 단어 단위 모델링에서는 같은 크기의 벡터로 임베딩 하기 때문에, 즉 같은 수의 파라미터로 표현하기 때문에, 모델이 효율적이지 못합니다.

그래서 생각을 한게, 그냥 Char-level로 모델링하자는 거죠. 당시에 이런 아이디어를 냈을 때, 주변에서 이러이런 단점이 있다를 말해줬었는데, 그중 첫번째가, Char 모델링을 통해서, 길면서도 말이되는 시퀀스를 생성할 수 있느냐, 두번째는, 단어들은 사실 High level abstract가 굉장히 잘 되있는건데, Char의 배열을 보고 이것의 의미를 알 수 있느냐-라는 문제입니다. Quiz Quit 이런 식으로 비슷한 스펠링임에도 의미가 확 달라지는데, 이걸 어떻게 학습시킬 것이냐-하는 거죠. 세번째는, 문장을 Char 단위로 나누면, 길이가 굉장히 길어지는데 이걸 효율적으로 다룰 수 있느냐-하는 겁니다. 영어 같은 경우에는 1개 단어가 5~6개 Char로 구성되었고, 언어마다 이건 더 짧아질 수도, 길어질 수도 있습니다. 쨋든 단어 단위보다는 길이가 훨씬 길어지겠죠.

그래서 이에 대답해보고자 했습니다. 첫번째, Char 모델링을 통해 길고, 논리 정연한 시퀀스를 생성할 수 있는가? 이를 위해서, 먼저 BPE sequence를 인풋으로 하는 것은 유지하되, 타겟을 Char sequence로 바꿔서 각각 학습을 시켜봤습니다. 결과적으로는, 기존 BPE에 비해 더 좋은 결과가 나왔죠. CNN과 RNN 그리고 어텐션을 활용했던 앞의 방법론이, 길어진 문장을 충분히 잘 이해한다는게 확인이 된거죠. 이게 확인이 된 순간, 그럼 인풋도 Char 단위로 바꿔봐야지 했죠.

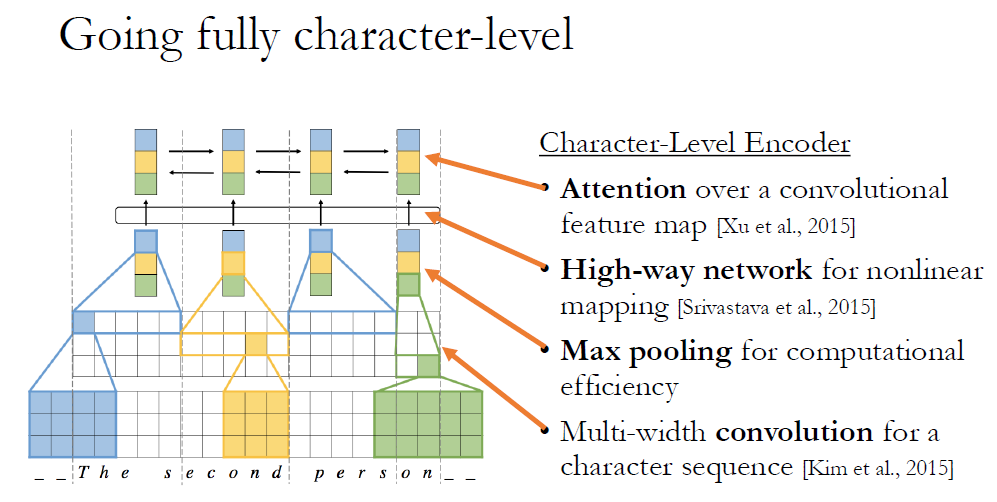
그런데 앞서 말했듯이, 어떤 Char sequence(스펠링)로 부터 의미를 이끌어 내는 작업이 굉장히 Non-linear하기 때문에 이걸 어떻게 처리할지가 굉장히 어려웠구요. 또 Self attention의 단점인 복잡도가 길이의 제곱으로 늘어난다는 점 때문에 고민을 했었죠. 그에 대한 방안으로, Sentence representation을 뽑을 때 Conv와 Recurrent를 같이 쓰자는 아이디어를 냈습니다.

그래서, Char level Encoder를 만들때 먼저 CNN을 통과시킵니다. Conv가 잘 하는게, 굉장히 지역적인 패턴들을 캡쳐하죠. 다만 Char 가 몇 개가 모여서 의미있는 조합이 될지 모르니까, Multi-width Conv를 적용하고. 다음에 Pooling을 진행합니다. 이렇게 하면서 모델링도 잘하고, 계산 효율성도 잡았죠. 그 다음에는 Non-linear한 의미를 추출하기 위해 딥한 네트워크를 사용하고, 다음에는 BiLSTM과 함께 Attention을 적용시킵니다. 이렇게하면, 다음 과정은 우리가 봤던 것과 똑같아요.
그렇게 해봤더니, 결과가 좋았습니다. 언어마다 당연히 차이가 있지만, 높은 순위를 기록하였고, 사람이 테스트 했을 때도, 전반적으로 Char-Char 모델이 좋았습니다.

결과를 보시면, 단어 단위 모델링에서의 다양한 문제점도 사라집니다. 스펠링 실수 문제, 처음 보는 합성어도 잘 이해하구요.

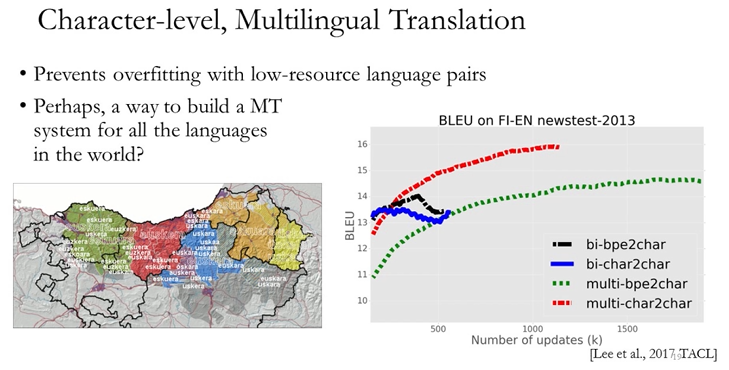
그렇게 보고 나니, Multilingual Translation으로 시선이 갔습니다. 그냥 다양한 언어로 구성된 Source language를 모델에 넘겨주고, 영어로 번역하라고 훈련을 시킨 다음, 테스트를 해보니, 언어별로 따로따로 모델을 학습시켰을 때보다, 한 번에 학습시킨 경우가 더 좋은 결과가 나왔습니다. 특히 자료가 적은 경우 더 그랬죠. 이게 된다는건, 서로다른 Modality가 들어 왔을 때, 각 언어마다 공유되는 어떤 특성을 잘 잡아낸다는 의미겠죠.

그래서 아래 예제들 처럼, 한 문장에 여러 언어가 섞여있어도, 잘 번역을 하게 되는거죠. 최근 페이스북, 구글 등도 다 이런 Multilingual Translation을 적용하고 있어요.

결국 이런 시스템이, 기계 번역이 나아갈 방향성이라고도 생각합니다. 이상입니다.
'머신러닝 > [딥러닝을 이용한 자연어 처리]' 카테고리의 다른 글
| Real-Time Translation Learning to Decode (0) | 2020.04.25 |
|---|---|
| Meta-Learning of Low-Resource Neural Machine Translation (0) | 2020.04.24 |
| Questions (0) | 2020.04.22 |
| Learning to Describe Multimedia (0) | 2020.04.22 |
| RNN Neural Machine Translation (0) | 2020.04.21 |


