학습목표
자연어 처리에서 기계번역 문제를 다뤄보기 전에, 우선 기계번역의 역사를 들어봅니다.
핵심키워드
- 기계번역(Machine Translation)
- 룰 기반 기계번역(Rule-based Machine Translation)
- 통계 기반 기계번역(Statistical Machine Translation)
- 신경망 기반 기계번역(Neural Machine Translation)
- 소스 언어(Source Language)
- 타겟 언어(Target Language)
학습하기
자 여태까지 Language model을 공부해봤는데, 제가 처음에 LM를 설명할 때, LM이 스코어링에도 사용이 되지만, 이게 결국 Generation의 문제를 해결할 수 있게 된다. 했었는데요, 지금부터는 Seq2Seq, Neural machine translation이라는 것에 대해 말해보겠습니다. Machine translation, 기계번역 이미 여러 분야에서 활용되고 있죠. 구글 번역기도 있고, 네이버 파파고도 있고. 역활은 어떤 문장과 원하는 언어가 들어왔을 때, 어떤 문장을 원하는 언어로 번역해주는 거죠. 근데 이게 재밌는게, 기계번역이라고 하지만, 이걸 통해서 Seq2Seq의 길이 열렸어요.
우선 그 역사에 대해서 알아봅시다. 이걸 알게되면, 왜 Neural Net이 좋은지 한 눈에 보일겁니다. 사람이 생각하는 바를 순서데로 모델링하면 아래 사진과 같았습니다. 이게 Rule-based machine learning인데,
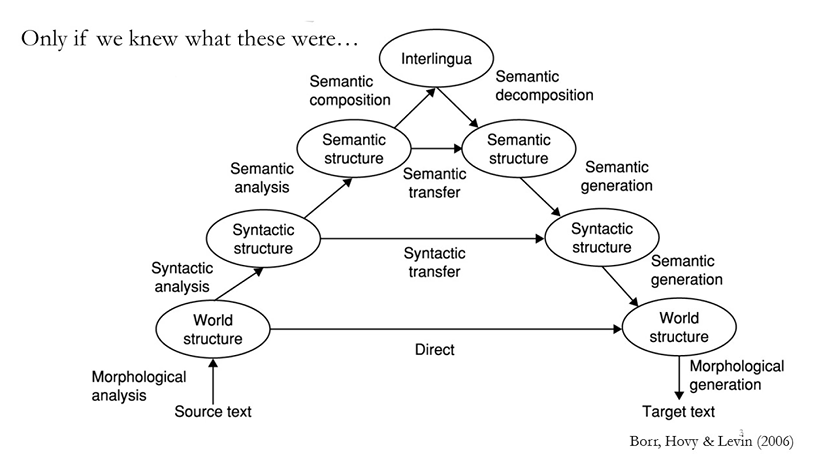
어떤 소스 언어가 들어오면, 의미단위로 분할하고, 어문학적으로 분석하고, 의미적으로 분석하고, 그 의미를 다시 종합해서, 최종적인 어떤 의미를 찾아내고, 이걸 다시 역순으로 풀어나감으로써 타겟 언어를 도출해내는. 굉장히 복잡하죠. 이런 모듈들을 한 200~300개를 만들어서 잘 붙이면 번역이 잘 되지 않을까-라고 예전엔 생각했었습니다. 그리고 약 10년 20년만에, 이런 어문학적 접근으로는 불가능하다. 라고 밝혀졌습니다. 그러다가 1988년 IBM에서, 아 이렇게 접근해서는 안되겠다. 통계적으로, 정보 이론을 믹스해서 어떻게 처리해보자. 그렇게 통계적인 기계 번역이 시작되었습니다. (물론 Rule-based MT도 결국 좁은 범위 내에서 활용되기도 합니다.) 쨋든, 통계적인 기계 번역이 결국 머신 러닝을 이용하자는 건데요.

더 나아가서, Neural Net을 사용하자는 의견이 무려 87년에 등장했었습니다. 인풋을 받고 그걸 인코딩 해서 = Sentence representation을 뽑아내서, 아웃풋으로 다른 언어로 번역하는 그런 개념이죠. 당시에는 데이터가 부족해서 3310개의 영어, 스페인어 쌍을 이용해서, 훈련을 시켜봤구요. 물론 당시 결과는 쓸만하지는 않았겠죠. 여러 환경이 부족했으니까. 그러다가 92년. 아주 비슷한 Neural Net을 제기합니다. 물론 당시에 200개 샘플로 훈련을 해서, 큰 데이터에도 동일하게 가능하냐 라는 문제에 대해 검증이 될 수 없었습니다. 그러면서 Neural Net은 잊혀졌고, 통계기반의 IBM의 Model이 확 떠버렸습니다. 그러다 또 5년 뒤, 2개의 비슷한 Neural Net을 활용한 MT논문이 나왔고, 또 5년 뒤, Neural Net을 활용한 MT논문이 나오게 됩니다.
2006년에 나온 내용은, IBM모델의 결과에 Neural Net을 적용하자는 의견이었습니다. 통계기반의 IBM 모델은 소스 언어로부터 스코어링을 진행한 문장 후보군을 k개 뽑고, 그 중 가장 높은 점수의 문장을 출력하는 방식이었는데, 한 연구원이 보기에 이게 별로 안좋아보이더라였던거죠. 그래서 그 후보를 Neural Net을 통해 조금 더 좋은 문장을 찾고자했습니다. 이후 2014년, Neural Net을 확률 기반 모델의 일부로 병합시키자는 의견을 제시했고, 결과는 성공적이었습니다. 이후에는 아예 Neural Net을 통해서 소스 언어를 타겟 언어로 출력할 수 있게 되었습니다.
그래서 머신 번역이 뭐냐를 다시보면, 굉장히 간단합니다. 아래 그림처럼, 어떤 문장이 주어졌을 때, 어떤 문장이 번역본이냐 하는 걸 찾아내면 되는 분류문제죠.

'머신러닝 > [딥러닝을 이용한 자연어 처리]' 카테고리의 다른 글
| RNN Neural Machine Translation (0) | 2020.04.21 |
|---|---|
| Encoder & Decoder (0) | 2020.04.20 |
| Summary (0) | 2020.04.18 |
| Questions (0) | 2020.04.17 |
| Long Term Dependency (0) | 2020.04.15 |

