하나의 머신 러닝 모델을 구성하는 것은 사실 굉장히 간단합니다. 데이터를 분리하고, 모델을 구성하고, 훈련하고, 평가한다. 특히 멋진 라이브러리를 활용하면 10줄 남짓한 코드로 이 모든 과정을 해결하는 것이 가능하지요. 물론 모델을 개선하기 위해 세부적으로 들어가면 데이터를 분리하기전 Feature engineering도 선행되어야하고, 데이터를 어떻게 분리하는 것이 가장 좋은 효과를 낼지, 모델을 구성하는 Hyper Parameter는 어떻게 조절해야할지 등 많은 것이 과제로 남습니다만, 베이스는 같습니다. 이번에는 그 중에서 마지막 단계. 평가하는 과정에서 사용되는 교차 검증 기법에 대해 설명하겠습니다.
가장 단순한 모델 평가
어떤 훈련 데이터로 학습된 모델을 평가하려면, 당연히 평가용 데이터가 있어야겠지요. 그래서 보통 주어진 데이터가 X, y 라면, 이를 X_train, y_train, X_test, y_test로 분리하게 됩니다. 아래 그림과 같습니다.

(X_train, y_train, 이하 훈련 데이터) 을 통해 모델을 학습시키고, (X_test, y_test, 이하 테스트 데이터)를 통해 계산한 스코어로 모델을 평가한다. 라는 목적에 취합합니다만, 가장 쉽게 떠올릴 수 있는 만큼 두 가지 단점을 가지고 있습니다. 첫째는, 이게 정말 모델의 성능을 평가할 수 있는가-하는 문제입니다. 나는 최종적으로 테스트 데이터로 계산된 스코어를 바라볼텐데, 만약 테스트 데이터가 전체 데이터를 대표할 수 없게 샘플링 되었다면 어떨까요. 극단적인 분류의 예시로, 훈련 데이터의 y는 0,1,2 등의 값이 있었는데, 테스트 데이터의 y는 1밖에 없습니다. 이러면 올바른 테스트 스코어가 계산될 수 없겠죠. 때문에 전체 데이터셋을 랜덤하게 섞고 데이터를 분할하거나, 더 나아가 분류의 경우 y 라벨이 균등하게 나눠질 수 있게끔 만들 수 있습니다만, 그럼에도 불구하고 운 나쁘게 테스트 데이터가 한 쪽으로 치우쳐진 형상을 띌 수도 있겠습니다. 두번째로는, 우리는 결국 테스트 스코어를 보고 계속 모델을 수정해나갈텐데, 이건 결국 모델을 하나의 테스트 데이터에만 적합하게 만드는, 또다른 과적합(Overfitting)을 이끌어냅니다. 전혀 새로운 데이터가 나왔을 때 오히려 모델이 제 구실을 못하는 상황이 생기겠지요. 결국 하나의 테스트 데이터를 사용하게 되면서 생기는 어쩔 수 없는 단점입니다.
그럼 어떻게 하라고?
이에 대한 대안이 교차 검증(Cross Validation)입니다. 하나의 테스트 데이터가 문제였으니, 여러 테스트 데이터를 써보자는 개념입니다. 그러나 단순히 테스트 데이터를 늘리면, 학습 데이터가 적어지는 trade-off 관계에서 벗어나고자 했습니다.

때문에 이렇게, 같은 데이터셋을 여러 번(k=4) 분할하여, 훈련 데이터와 테스트 데이터를 나눔으로써, 모델의 스코어를 4번 계산하고, 이를 평균(또는 다른 계산)내어 사용하자는 아이디어가 있습니다. 이런 식으로 여러 데이터의 조합으로 모델의 성능을 평가(검증)하는 기법이 교차 검증(Cross Validation)이며, 이처럼 전체 데이터셋을 k개로 나누는 교차 검증을 k-Fold Cross validation이라 합니다. 이 경우에도 랜덤 셔플과 계층 옵션을 주는 것이 당연히 가능합니다. 또 k-Fold CV 외에도 다른 Leave out CV 등이 존재하지만, 핵심 개념은 유사합니다.
그런데 시계열 데이터의 경우에는
시계열 데이터를 다루는 경우에는 조금 다릅니다. 과거의 데이터를 통해 미래의 데이터를 예측해야하는 상황에서는 랜덤 셔플도 불가능하며, 과거와 미래를 오가며 학습하는 것도 애매합니다. 때문에 아래와 같은 교차 검증 방법이 등장하였습니다.
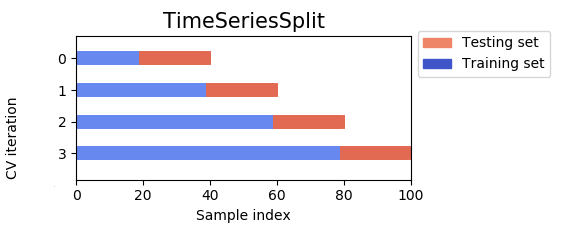
앞 단의 데이터부터 쌓아가며 훈련 데이터와 테스트 데이터를 분할해 사용하는 방식때문에 Stacked k-Fold Cross validation이라고도 하고, Sklearn에서는 TimeSeriesSplit라고 합니다.
'머신러닝' 카테고리의 다른 글
| Model-agnostic 이란? (0) | 2021.06.06 |
|---|---|
| 파이썬 비트 연산(Bitwise Operation) (0) | 2020.05.04 |
| 정규 표현식(Regular Expressions) 및 문자열 다듬기 (0) | 2020.05.02 |